|
内存布局看似是笔记布局底层和距离应用程序开发比较遥远的概念集合,但其对前端应用的功能实现颇具现实意义。从业务模块至插件,无处不涉及到跨语言互操作。浅聊甚至,做个文本数据的程序字符集转换也得调用操作系统链接库,因为这意味着更小的发布文件。而与内存布局正是内存跨(计算机)语言数据结构的基础。 大约两个月前,在封装闭包(不是笔记布局函数指针)过程中,我重新梳理了内存布局知识点。然后,就有冲动写这么一篇长文。浅聊今恰逢国庆八天长假,汇总我之所知与大家分享。程序开始正文... 变量值在内存中的内存存储信息包含两个重要属性
而这两个值都不是在分配内存那一刻的“即兴选择”。而是笔记布局,遵循着一组规则:
对齐位数必须是浅聊的自然数次幂。即,且是程序的自然数。 存储宽度是有效数据长度加对齐填充位数的总和字节数 — 这一点可能有点儿反直觉。 ,与的计量单位都是“字节”。 正是因为,与之间存在倍数关系,所以程序对内存空间的利用一定会出现冗余与浪费。这些被浪费掉的“边角料”则被称作【对齐填充】。对齐填充的计量单位也是字节。根据“边角料”出现的位置不同,对齐填充又分为
文字抽象,图直观。一图抵千词,请看图
如果【对齐位数】与【存储宽度】在编译时已知,那么该类型就是【静态分派】。于是,
若【对齐位数】与【存储宽度】在运行时才可计算知晓,那么该类型就是【动态分派】。于是,
存储宽度的对齐计算若变量值的有效数据长度正好是该变量类型【对齐位数】的自然数倍,那么该变量的【存储宽度】就是它的【有效数据长度】。即,。 否则,变量的【存储宽度】就是既要大于等于【有效数据长度】,又是【对齐位数】自然数倍的最小数值。
基本数据类型基本数据类型包括,,,,,,,,,,,,,,和。它们的内存布局在不同型号的设备上略有差异
瘦指针瘦指针的内存布局与类型是一致的。因此,在不同设备和不同架构上,其性能表现略有不同
胖指针胖指针的存储宽度是类型的两倍,对齐位数却与相同。就依赖于设备/架构的性能表现而言,其与瘦指针行为一致:
数组,切片和就是满足编码规范的增强版切片。 存储宽度是全部元素存储宽度之和 对齐位数与单个元素的对齐位数一致。 单位类型存储宽度 = 对齐位数 = 所有零宽度数据类型都是这样的内存布局配置。 来自【标准库】的零宽度数据类型包括但不限于:
复合数据结构的内存布局描绘了该数据结构(紧内一层)字段的内存位置“摆放”关系(比如,间隙与次序等)。在层叠嵌套的数据结构中,内存布局都是就某一层数据结构而言的。它既承接不了来自外层父数据结构的内存布局,也决定不了更内层子数据结构的内存布局,更代表不了整个数据结构内存布局的总览。举个例子, 仅只代表最外层结构体的两个字段和是按内存布局规格“摆放”在内存中的。但,并不意味着整个数据结构都是内存布局的,更改变不了字段的类型是内存布局的事实。若你的代码意图是定义完全的结构体,那么【原始指针】才是该用的类型。 内存布局核心参数自定义数据结构的内存布局包含如下五个属性
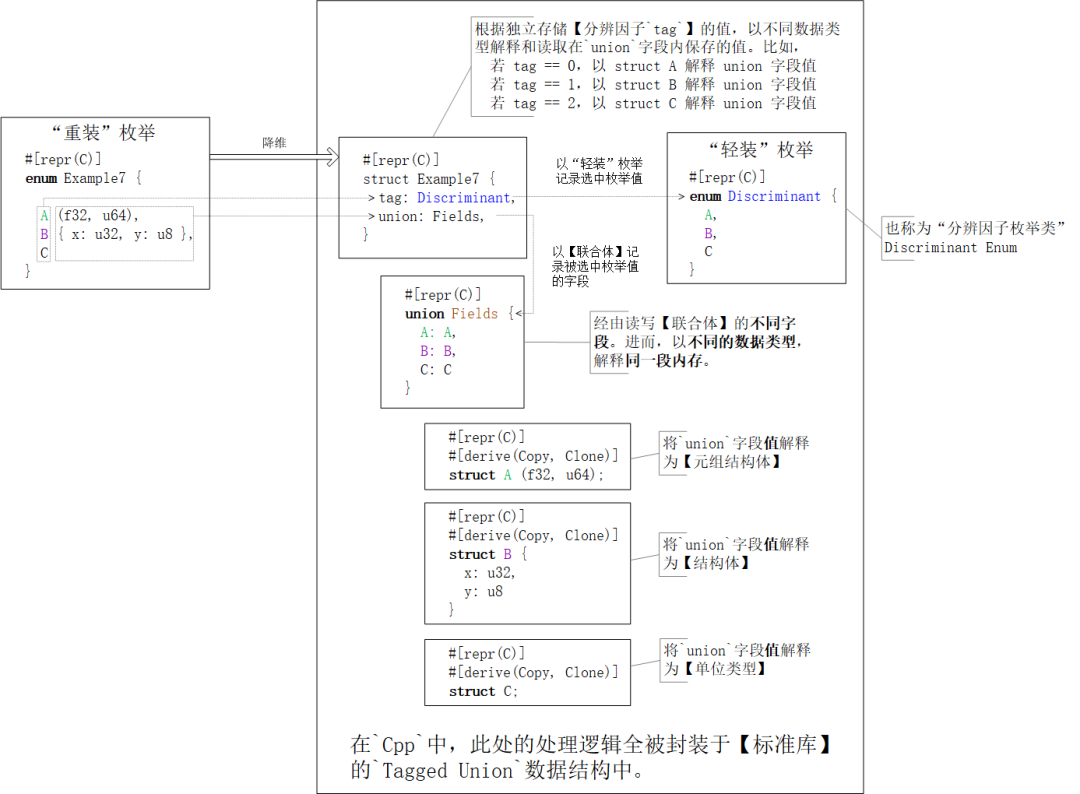
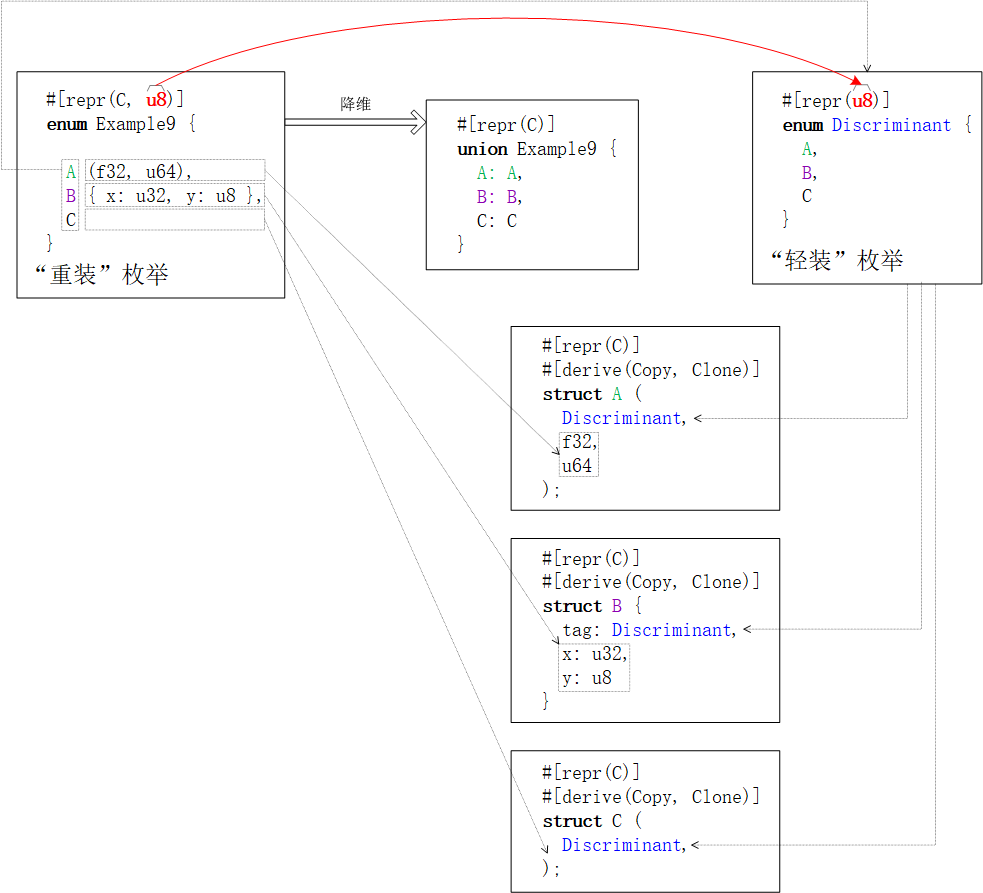
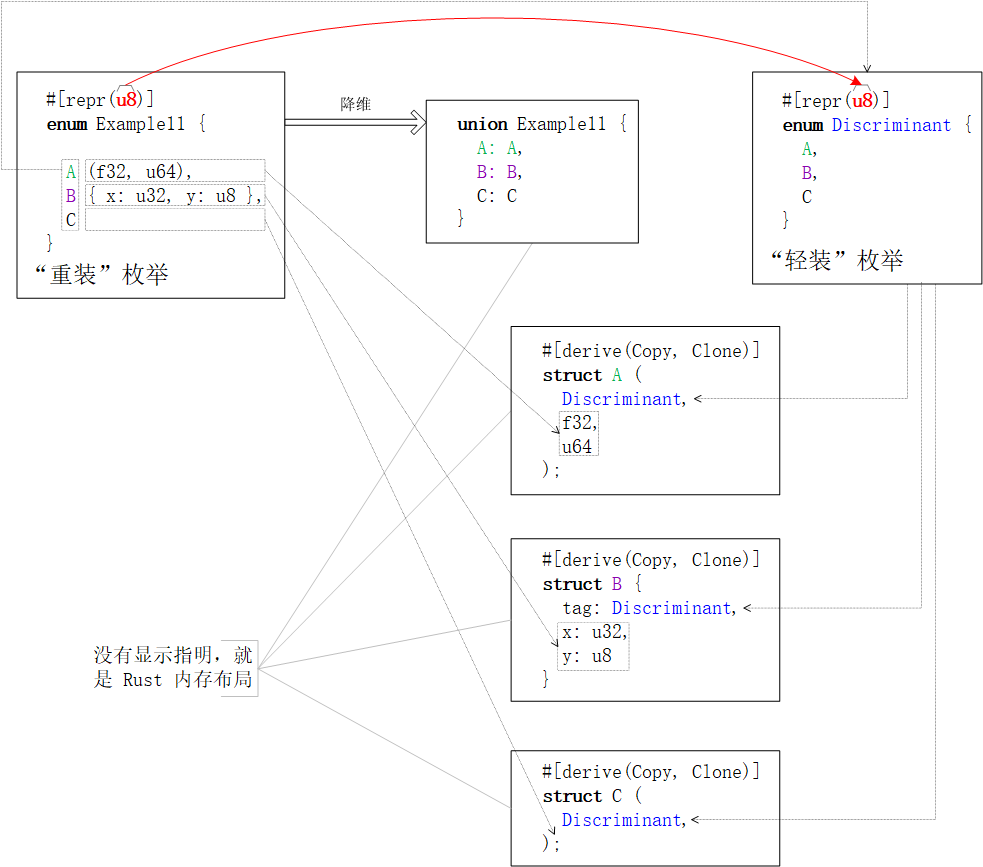
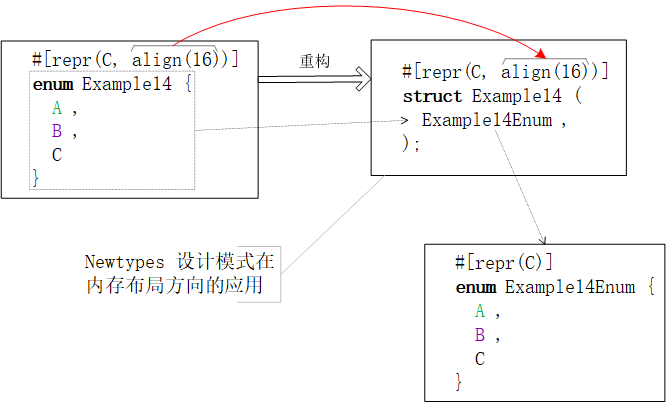
自定义枚举类的内存布局一般与枚举类分辨因子的内存布局一致。更复杂的情况,请见下文章节。 预置内存布局方案编译器内置了四款内存布局方案,分别是
透明·内存布局
预置内存布局方案对比相较于内存布局,内存布局面向内存空间利用率做了优化 — 省内存。具体的技术手段包括编译器
以中间格式为桥的内存布局虽然实现了跨语言数据结构,但它却更费内存。这主要出于两个方面原因:
以费内存为代价,内存布局赋予数据结构的另一个“超能力”就是:“仅通过变换【指针类型】就可将内存上的一段数据重新解读为另一个数据类型的值”。比如,被允许指向任意数据类型的变量值 例程。但在内存布局下,需要调用专门的标准库函数std::intrinsics::transmute()才能达到相同的目的。 除了上述鲜明的差别之外,与内存布局都允许【对齐位数】参数被微调,而不一定总是全部字段中的最大值。这包括但不限于:
结构体的内存布局结构体算是最“中规中矩”的数据结构。无论是否对结构体的字段重新排序,只要将它们一个不落地铺到内存上就完成一多半功能了。所以,结构体存储宽度是全部字段之和再(自然数倍)对齐于【结构体对齐位数】的结果。有点抽象上伪码 相较于内存布局优化算法的错综复杂,我好似只能讲清楚内存布局的始末: 首先,结构体自身的对齐位数就是全部字段对齐位数中的最大值。 其次,声明一个(可修改的)游标变量以实时跟踪(参照于结构体首字节地址的)字节偏移量。游标变量的初始值为表示该游标与结构体的内存起始位置重合。 接着,沿着源码中字段的声明次序,逐一处理各个字段:
然后,在结构体内全部字段都被如上处理之后,
至此,结构体的内存布局结束。然后,就能够拿着这套“策划案”向操作系统申请内存空间去了。由此可见,每次【对齐】处理都会在有效数据周围“埋入”大量空白“边角料”(学名:对齐填充位)。但出于历史原因,为了完成与其它计算机语言的互操作,这些浪费还是必须的。下面附以完整的伪码辅助理解 联合体的内存布局形象地讲,联合体是给内存中同一段字节序列准备了多套“数据视图”,而每套“数据视图”都尝试将该段字节序列解释为不同数据类型的值。所以,无论在联合体内声明了几个字段,都仅有一个字段值会被保存于物理存储之上。从原则上讲,联合体的内存布局一定与占用内存最多的字段一致,以确保任何字段值都能被容纳。从实践上讲,有一些细节处理需要斟酌:
举个例子,联合体内包含了与类型的两个字段,那么的内存布局就一定与的内存布局一致。再举个例子, 看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
字段的
联合体的
再来一个更复杂点儿的例子, 同样,在看答案之前,不防先心算一下,程序向标准输出打印的结果是多少。演算过程如下:
联合体的
不经意的巧合思维敏锐的读者可以已经注意到:单字段【结构体】与单字段【联合体】的内存布局是相同的,因为数据结构自身的内存布局就是唯一字段的内存布局。不信的话,执行下面的例程试试 枚举类的内存布局突破“枚举”字面含义的束缚,的创新使与传统计算机语言中的同类项都不同。枚举类
在Rust References一书中,
禁忌:内存布局的枚举类必须至少包含一个枚举值。否则,编译器就会报怨:。 “轻装”枚举类的内存布局因为“轻装”枚举值的唯一有效数据就是“记录了哪个枚举项被选中的”分辨因子,所以枚举类的内存布局就是枚举类【整数类型】分辨因子的内存布局。即, 别庆幸!故事远没有看起来这么简单,因为【整数类】是一组数字类型的总称(馁馁的“集合名词”)。所以,它包含但不限于 Rust | C | 存储宽度 | |
| u8 / i8 | unsigned char / char | 单字节 | |
| u16 / i16 | unsigned short / short | 双字节 | |
| u32 / i32 | unsigned int / int | 四字节 | |
| u64 / i64 | unsigned long / long | 八字节 | |
| usize / isize | 没有概念对等项,可能得元编程了 | 等长于目标架构“瘦指针”宽度 | |
| C | Rust 元属性 | ||
|---|---|---|---|
| unsigned char / char | #[repr(u8)] / #[repr(i8)] | ||
| unsigned short / short | #[repr(u16)] / #[repr(i16)] | ||
| unsigned int / int | #[repr(u32)] / #[repr(i32)] | ||
| unsigned long / long | #[repr(u64)] / #[repr(i64)] |